tl;dr Link to heading
- I implemented a todo backend in R with plumber.
- Use Rocker with PPAs for fast container builds. Dirk Eddelbuettel demonstrates how at this link.
todo backend Link to heading
Todo-Backend is “a shared example to showcase backend tech stacks”, inspired by the front-end todomvc.
It’s a good way to get a sense for how you might implement similar functionality in other languages.
I’d read some other posts on setting up plumber apis so I decided to give it a shot.
the tests Link to heading
Creating a todo backend requires passing sixteen tests, which confirm that your API is implemented according to the specification.
the stack Link to heading
I made my choices about hosting and database providers based on where I would be able to run the API without paying for it. I tried Google Cloud Run, which can host containers that automatically scale to 0 if your API is not receiving any requests, but mysterious failures led me to use Heroku instead.1
I also decided to use a relational database to store the data to get some more practice with DBI. As far as I can tell, leaving even the smallest Google Cloud SQL instance running indefinitely would have cost a few dollars a month, so instead I went with a free elephantsql instance.
CORS Link to heading
The tests require your API to support cross-origin resource sharing.
the plumber docs illustrate how to do this for Access-Control-Allow-Origin, but additional headers have to be set in order for the API to respond correctly to OPTIONS requests, as demonstrated here.
connecting to the database Link to heading
Following the 12-factor best practice, the database connection information is accessed through environment variables.
For development, these are stored in an .Renviron file2, which both git and docker are instructed to ignore.
I went through several rounds of testing where I would try the database functions interactively, they would work as expected, and then once I built and deployed the container the database connection would fail.
A solution to this problem is to use a pool.
In the file that starts the container I initialize the connection:
con <-
dbPool(
drv = RPostgres::Postgres(),
dbname = Sys.getenv("DB_NAME"),
host = Sys.getenv("DB_HOST"),
port = 5432,
user = Sys.getenv("DB_NAME"),
password = Sys.getenv("DB_PASS"),
maxSize = 5 # connection limit for elephantsql instance class
)
And then in the functions that query the database, I pass this connection object along:
get_todos <- function(con) {
dbGetQuery(con, "SELECT * FROM todos")
}
Some functions emit warnings if a “statement” rather than a “query” (which would return data) is sent; to suppress that warning, you can explicitly check out and then return a connection from the pool:
delete_todos <- function(con) {
pool <- poolCheckout(con)
rs <- dbSendQuery(pool, "DELETE FROM todos")
dbClearResult(rs)
poolReturn(pool)
}
The pool also handles what might otherwise be annoying details to manage. For example, I set a maximum connections limit that matches the number of connections allowed by the size of my database connection instance.
know your default arguments Link to heading
For the first several tests, no “order” item is provided, but later tests supply and modify the order, title, and completion status. It took me a few tries to arrive at a working specification of default arguments.3
First, the functions that query the database:
create_todo <- function(con, req, title, order = NULL, completed = FALSE) {
todo_order <- order %||% NA_integer_
...
}
update_todo <- function(con, id, title = NULL, order = NULL, completed = NULL) {
c(old_title, old_completed, old_order) %<-%
dbGetQuery(
con,
'SELECT title, completed, "order" FROM todos WHERE id = $1',
params = list(id)
)
...
}
Setting order, title, and completed to NULL indicate that they can be supplied as default arguments, but don’t have to be present, as shown in update_todo().
Then, within the function body you can test for whether the argument was supplied, as in create_todo().
By default, Plumber APIs will parse the body of a POST request.
The tests are sent to the API as JSON, so you can supply the keys of the object as arguments to the function.
Again, since order and completed are only set in some of the tests, the default should be set to NULL:
#' @get /
#' @post /
#' @delete /
function(req, res, title, order = NULL, completed) {
method <- req$REQUEST_METHOD
if (method == "POST") {
out <- create_todo(con, req, title, order)
res$status <- 201
return(out)
}
...
}
#' @get /<id:int>
#' @patch /<id:int>
#' @delete /<id:int>
function(req, res, id, title = NULL, order = NULL, completed = NULL) {
method <- req$REQUEST_METHOD
if (method == "PATCH") {
return(update_todo(con, id, title, order, completed))
}
...
}
Because the database functions are set up to check for null arguments, supplying order as an argument when the functions are called at the endpoint ensures that the right thing will happen.
fast docker builds Link to heading
first attempt: {renv} Link to heading
Are you using {renv}? It makes versioning your dependencies delightfully easy; check it out. However, using it with docker can be pretty slow.
Building a container by running renv::restore() took about 16 minutes.4
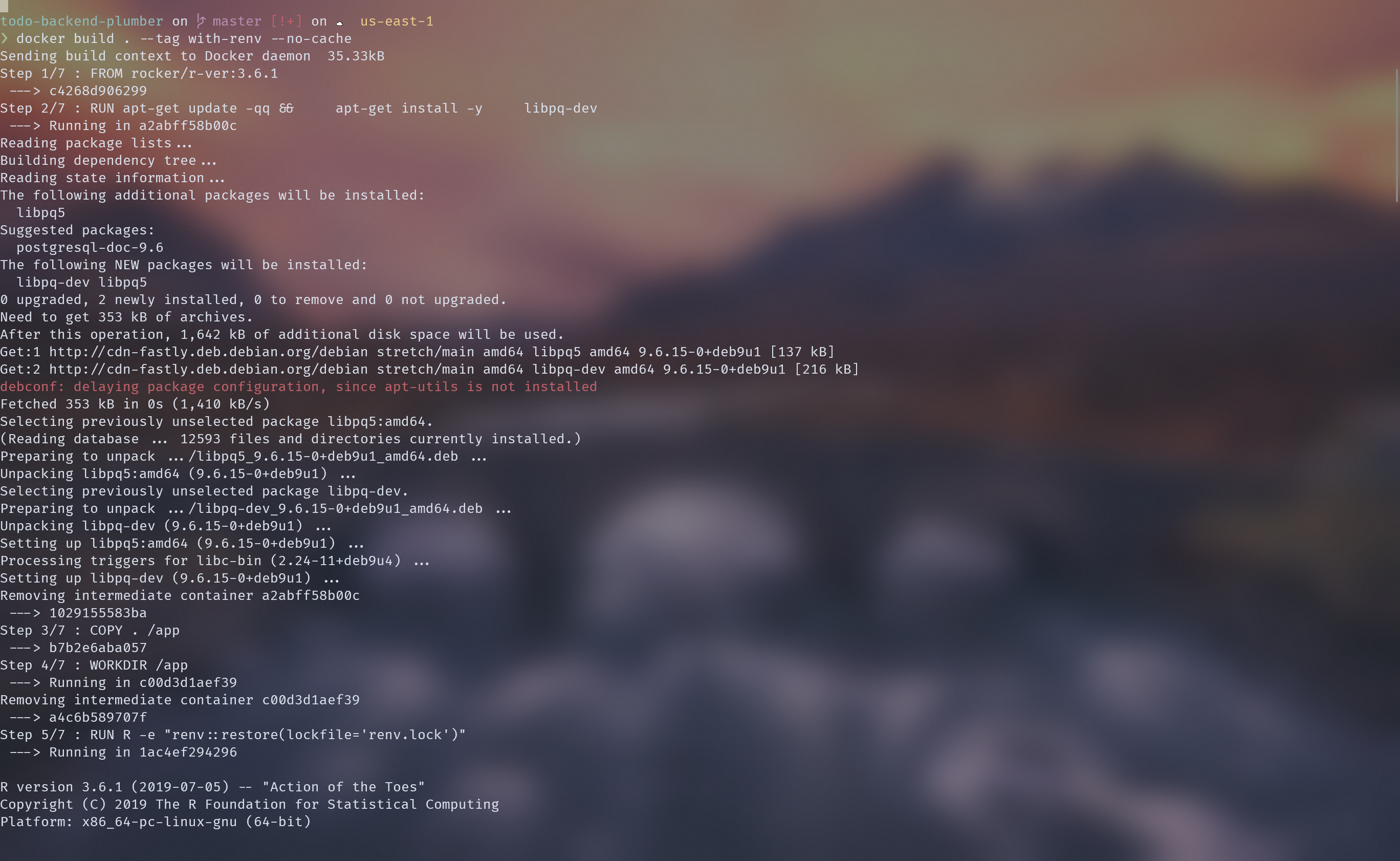
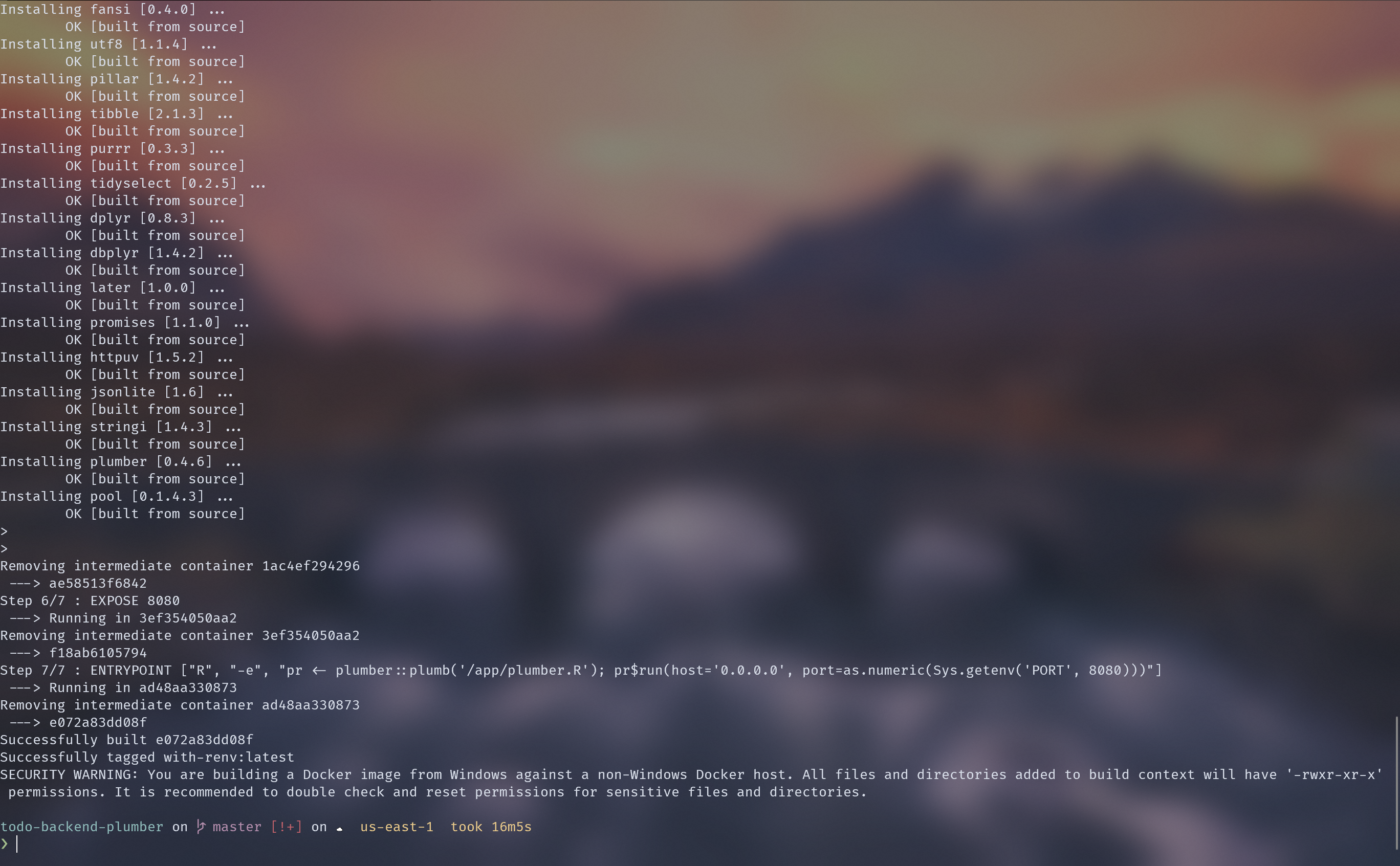
There is an article on the renv website about how to speed up package builds when using docker, but figuring out how to make use of the renv cache will have to be another blog post.
docker with PPAs Link to heading
PPAs are “personal package archives”.
In this case, the relevant personal archives are supplied by Dirk Eddelbuettel and Michael Rutter, and they contain R packages that can be installed as binaries rather than being compiled from source.
To use them, I switched to the rocker/r-ubuntu image and installed the relevant packages via apt-get.
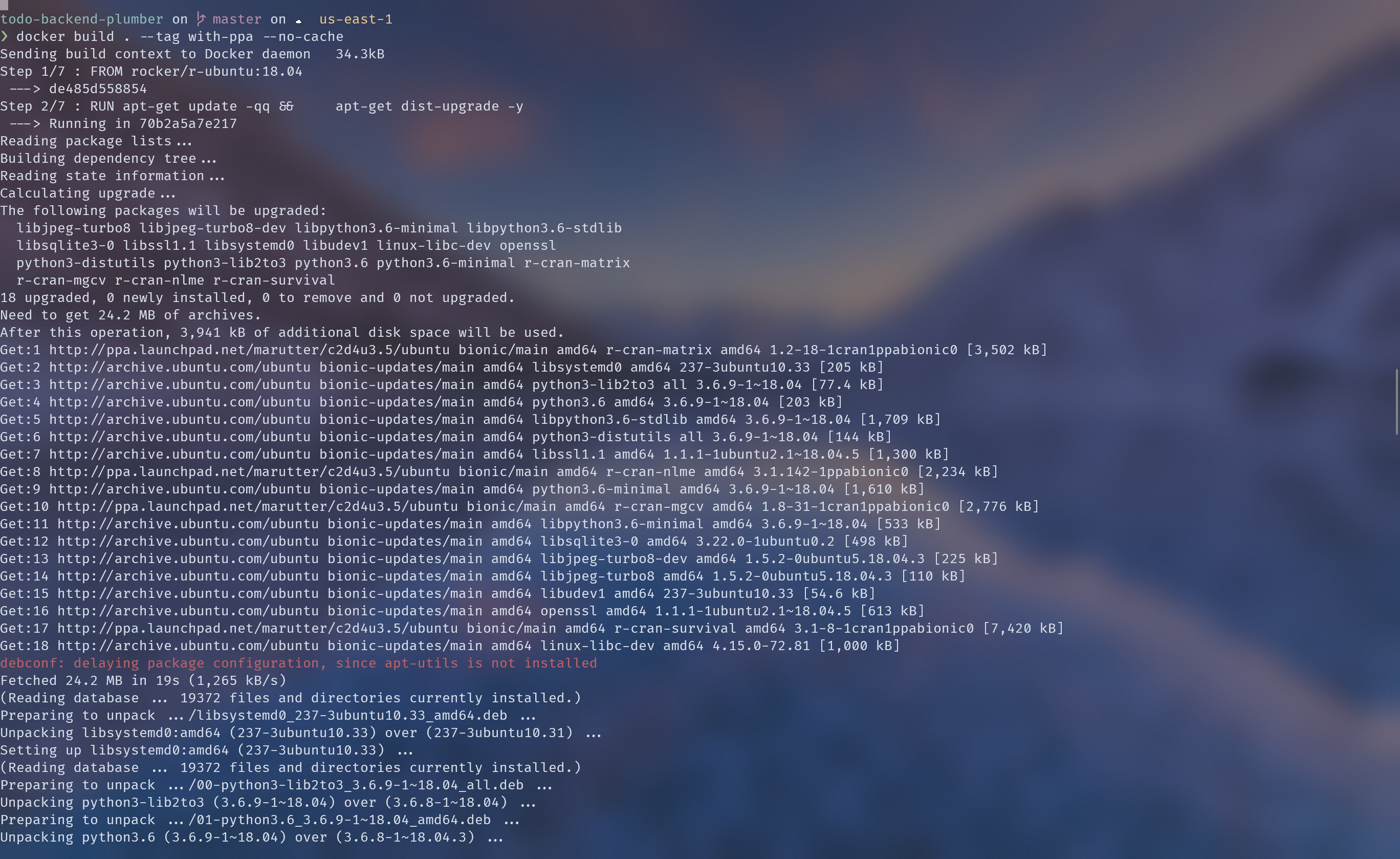
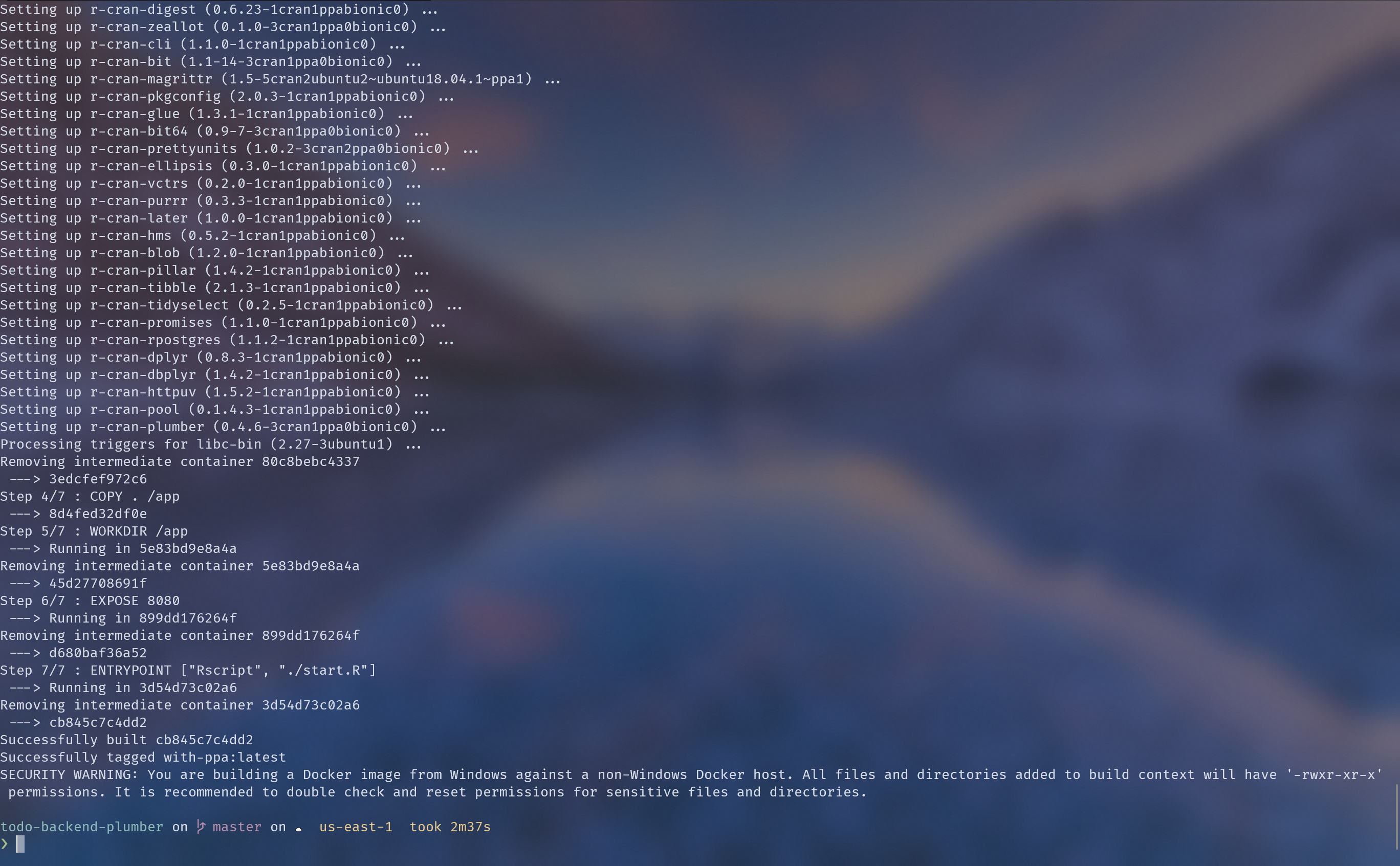
The build time drops to about 2.5 minutes.
If you’re paying for build minutes or worried about build timeouts, give rocker/r-ubuntu a look.
renv + PPAs Link to heading
Make sure to add the .Rprofile generated by renv to your .dockerignore file; otherwise renv will install itself when your R process starts, and your script will be unable to find your packages.
reasonable next steps Link to heading
better error handling Link to heading
Plumber is pretty graceful about generating 500 errors if there are bugs in your endpoint code, but more thoughtful error handling is never a bad thing.
make it a package Link to heading
There’s an example plumber api package on the RStudio Solutions Engineering Github page, which illustrates how to deploy API code as a package.
-
All of the tests pass when the api is served via
ngrokor when the container is deployed to Heroku, but when deployed to Google Cloud Run, some earlier tests pass but others fail with CORS issues. 🤷🏾♂️ ↩︎ -
Initially I tried used Gabor Csardi’s
{dotenv}, but it was not in the PPA. ↩︎ -
%||%, the “coalescing null,” is borrowed from rlang. I consulted a nodejs example that filled me with destructuring assignment envy, and since {RPostgres} comes with {zeallot} I decided to take advantage. ↩︎ -
I imagine there is a way to automate the installation of system requirements instead of doing this, but I’m not sure what it is. ↩︎